
Optimalidad asintótica de Thompson Sampling para bandidos aversos al riesgo
Un algoritmo de Thompson Sampling no paramétrico logra optimalidad asintótica en bandidos aversos al riesgo con recompensas subgaussianas.
Un algoritmo de Thompson Sampling no paramétrico logra optimalidad asintótica en bandidos aversos al riesgo con recompensas subgaussianas.

La combinación de Q* y Bellman completa no es suficiente para RL offline con cobertura parcial. Descubre el nuevo marco teórico y mejoras.
Descubre la nueva tasa minimax espacio-temporal para distribuciones suaves en Wasserstein. Ideal para investigadores y expertos en OT.

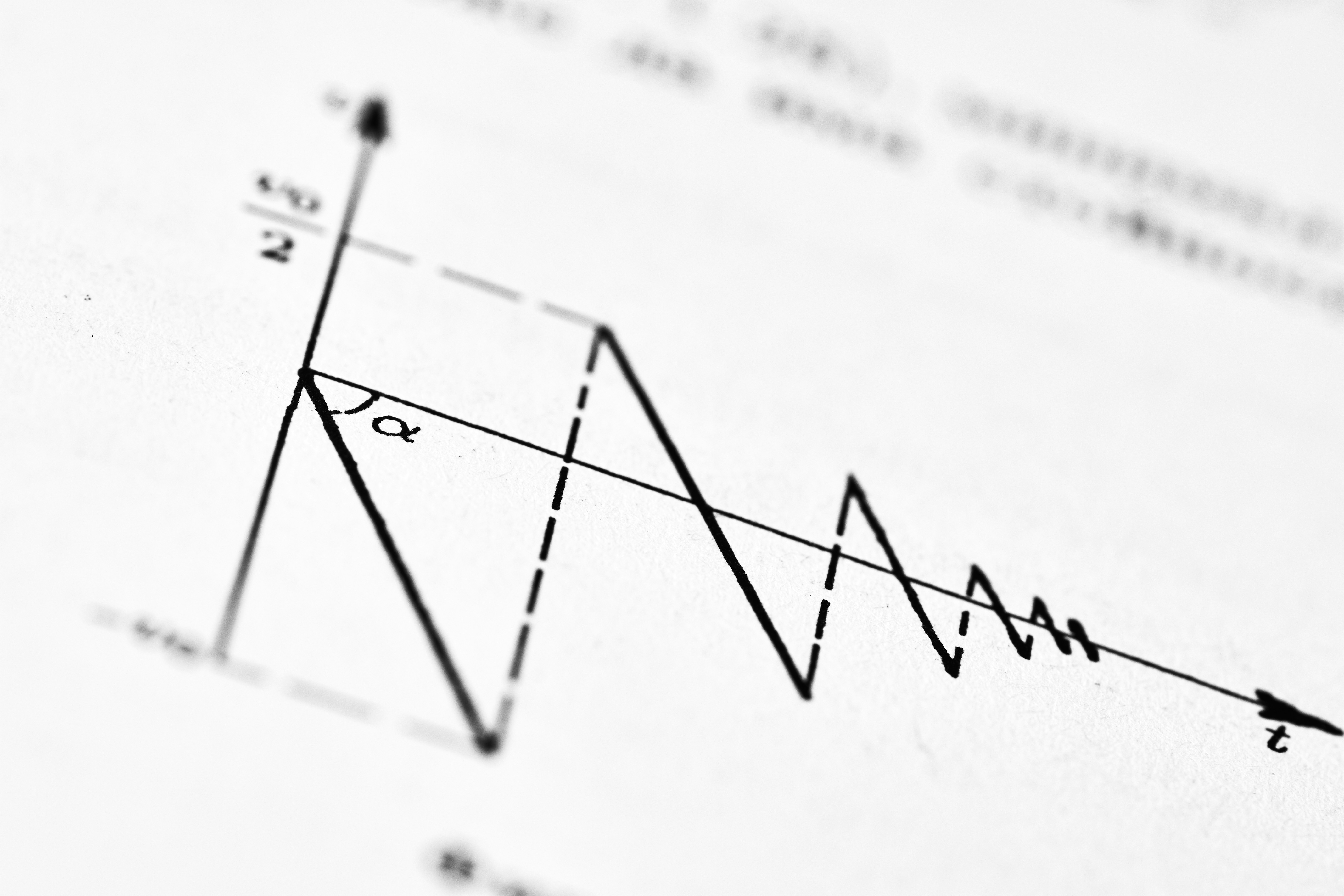
Descubre cómo el algoritmo ATC supera los desafíos del aprendizaje con múltiples puntos de cambio, logrando un rendimiento casi óptimo y evitando la confusión endógena.

Descubre la primera cota inferior para algoritmos basados en medias en bandidos con horizonte desconocido. Nuevos algoritmos competitivos y su relación con no-regret.

Descubre cómo optimizar certificados de cota inferior para distancia unitaria mediante algoritmos de optimización entera, mejorando la cota de Erdős a n^{1.0152

Descubre cómo los investigadores demostraron una cota de arrepentimiento de orden √T para el problema de degustación. ¡Lee el artículo!
Descubre un método asintóticamente óptimo para pruebas secuenciales en cadenas de Markov. Mejora límites inferiores y aplicaciones en MCMC y MDPs.
Nuevos acoplamientos no markovianos revelan cotas exactas de convergencia para difusiones de Langevin cinéticas, superando limitaciones previas en muestreo.
Aproxima divergencias-f con estadísticos de rango. Método rank-statistic para alta dimensión usando proyecciones aleatorias. Eficiente y validado.

Descubre cómo los límites informacionales afectan la optimización estocástica con gradientes de baja precisión: reducción a estimación gaussiana.